Contenido
- Definición - ¿Qué significa Apache Kudu?
- Una introducción a Microsoft Azure y la nube de Microsoft | A lo largo de esta guía, aprenderá de qué se trata la computación en la nube y cómo Microsoft Azure puede ayudarlo a migrar y administrar su negocio desde la nube.
- Techopedia explica Apache Kudu
Definición - ¿Qué significa Apache Kudu?
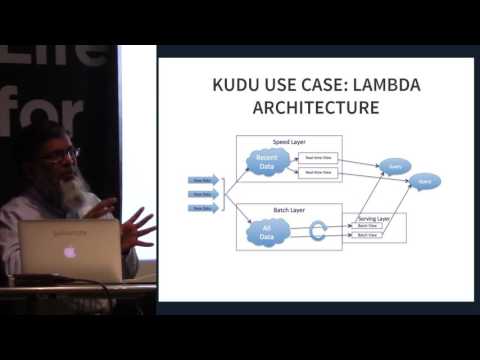
Apache Kudu es miembro del ecosistema de código abierto Apache Hadoop. Es un motor de almacenamiento de código abierto destinado a datos estructurados que admite acceso aleatorio de baja latencia junto con patrones de acceso analítico eficientes. Fue diseñado e implementado para cerrar la brecha entre el ampliamente utilizado Sistema de archivos distribuidos de Hadoop (HDFS) y la Base de datos HBase NoSQL. Aunque estos sistemas aún pueden resultar ventajosos, Apache Kudu puede satisfacer muchas cargas de trabajo comunes, ya que puede simplificar drásticamente su arquitectura.
Una introducción a Microsoft Azure y la nube de Microsoft | A lo largo de esta guía, aprenderá de qué se trata la computación en la nube y cómo Microsoft Azure puede ayudarlo a migrar y administrar su negocio desde la nube.
Techopedia explica Apache Kudu
Apache Kudu se desarrolló principalmente como un proyecto en Cloudera. La mayoría de las contribuciones hasta la fecha han sido realizadas por desarrolladores empleados por Cloudera. Durante su lanzamiento, solo se incluyeron binarios de conveniencia en los repositorios de Cloudera, sin embargo, adoptó el proceso de lanzamiento de la fuente de Apache Software Foundation (ASF) al unirse a la incubadora. Está específicamente diseñado para casos de uso que requieren análisis rápidos de datos rápidos. Fue diseñado para aprovechar el hardware de próxima generación y el procesamiento en memoria. Reduce significativamente la latencia de consulta para Apache Impala y Apache Spark. Distribuye datos a través de un motor de almacenamiento en columnas o mediante particiones horizontales, luego replica cada partición utilizando el consenso de Raft, lo que proporciona un tiempo medio de recuperación bajo y latencias de cola bajas.
Aunque Kudu es un producto diseñado dentro de la estafa del ecosistema Apache Hadoop, también admite la integración con otros proyectos de análisis de datos dentro y fuera del ASF.
Apache Kudu demuestra ser eficiente, ya que puede procesar cargas de trabajo analíticas en tiempo real en una sola capa de almacenamiento, lo que brinda a los arquitectos flexibilidad para abordar una variedad más amplia de casos de uso sin soluciones exóticas.